Dein PageSpeed-Score ist 100, trotzdem taucht deine Seite in keiner ChatGPT-Antwort auf. Das Problem ist nicht dein Content, sondern die Antwortzeit deines Servers. In zwei aktuellen Projekten habe ich Antwortzeiten zwischen 800ms und 1,5 Sekunden gemessen. Werte, bei denen AI-Crawler aufgeben. Dieser Artikel zeigt, wie du das für deine Seite prüfst, mit einer Ticket-Vorlage für SEOs und konkreten Config-Snippets für die IT.
Dieser Artikel hat zwei Teile: Der erste ist für SEOs und E-Commerce-Manager, mit Hintergrund, Checkliste und einer Ticket-Vorlage. Der zweite ist die technische Anleitung für deine IT.
- Das Problem: AI-Crawler warten nicht
- Warum das anders ist als klassisches SEO
- Wer crawlt dich? Die wichtigsten AI-Bots
- Vorbedingung: Blockierst du AI-Crawler?
- AccessLogs: Warum sie für AI-Sichtbarkeit unverzichtbar sind
- Prüf-Checkliste: 3 Fragen an deine IT
- Sonderfall: Shopify und Managed-Hosting-Plattformen
- Technische Umsetzung: Antwortzeiten im AccessLog erfassen
- Auswertung: AI-Crawler-Performance analysieren
- Logging-Pipeline statt jq
- Häufigste Ursachen langsamer Antwortzeiten
- Fazit
- Messen ist der erste Schritt. Optimieren der zweite.
Das Problem: AI-Crawler warten nicht
ChatGPT, Perplexity und Claude rufen Webseiten live ab, wenn ein Nutzer eine Frage stellt. Anders als Googlebot, der Seiten in seinen Index aufnimmt und später auswertet, holen diese Crawler dein HTML in Echtzeit.
Für die LLM-Betreiber gibt es zwei Gründe, langsame Seiten abzubrechen: Erstens wollen sie den Nutzer nicht warten lassen, der eine schnelle Antwort erwartet. Zweitens kostet jede offene Verbindung Ressourcen. Wenn ein Crawler hunderte Quellen pro Anfrage prüft, summieren sich langsame Server schnell zu einem teuren Problem. Also wird abgebrochen, und dein Inhalt taucht in keiner AI-Antwort auf.
Jérôme Salomon hat in einer Serverlog-Analyse gezeigt: 99% der Bot-Hits mit HTTP 499 in nginx-Logs kamen von einem einzigen User-Agent: ChatGPT-User. Die beobachtete Schmerzgrenze: rund 500 Millisekunden.
Johan von Hülsen hat diese Beobachtung auf dem OMT Summit 2026 unabhängig bestätigt: 500-800ms Server-Antwortzeit, dann macht ChatGPT den Deckel zu.
Wie schnell das Thema wächst, zeigen Cloudflare-Zahlen aus dem Zeitraum Mai 2024 bis Mai 2025. Um die Zahlen einzuordnen, hilft eine Unterscheidung zwischen zwei Arten von AI-Crawling:
- Indexierung/Training (GPTBot, ClaudeBot, PerplexityBot): Bots, die das Web systematisch abgrasen, um Modelle zu trainieren oder einen Suchindex aufzubauen. Zeitdruck ist hier gering. Der Bot kommt einfach morgen wieder. GPTBot-Traffic ist in diesem Zeitraum um 305% gewachsen.
- Nutzeranfragen in Echtzeit (ChatGPT-User, Claude-User, Perplexity-User): Ein Nutzer stellt eine Frage, der Crawler ruft deine Seite live ab, um die Antwort zu generieren. Hier zählt jede Millisekunde, weil der Nutzer wartet. ChatGPT-User-Traffic ist im selben Zeitraum auf das 29-Fache gestiegen.
Für die Antwortzeiten-Optimierung ist die zweite Kategorie entscheidend. Wenn ChatGPT-User deine Seite abruft und der Server zu langsam antwortet, wird eine andere Quelle zitiert. In Echtzeit, ohne zweiten Versuch.
Wichtig: Die 500ms sind eine Community-Beobachtung, kein offiziell dokumentierter Grenzwert. Weder OpenAI noch Anthropic veröffentlichen Timeout-Werte. Aber die Logik ist zwingend: AI-Anbieter müssen hunderte Quellen pro Anfrage prüfen. Wer zu langsam antwortet, fliegt aus der Auswahl.
Mein Richtwert: unter 200ms Antwortzeit anstreben. Unter 500ms sollte das Minimum sein.
Wer nginx als Webserver nutzt, hat beim Auswerten der AccessLogs einen nützlichen Indikator: den HTTP-Statuscode 499. Das ist kein offizieller HTTP-Standard, sondern ein nginx-spezifischer Code für „Client hat die Verbindung geschlossen, bevor der Server antworten konnte“. Genau das passiert, wenn ein AI-Crawler den Request abbricht. Wer Apache nutzt, sieht diesen Code nicht. Apache loggt abgebrochene Verbindungen mit dem zuletzt ermittelten Statuscode (oft 200), sodass ein Client-Abbruch im Log aussieht wie ein normaler Request. Apache hat zwar die Log-Variable %X, die den Verbindungsstatus anzeigt (X = abgebrochen, + = Keepalive, - = geschlossen), aber die ist nicht im Standard-LogFormat enthalten. Deshalb ist es umso wichtiger, die Antwortzeit selbst zu loggen, statt sich auf Statuscodes zu verlassen.
Warum das anders ist als klassisches SEO
| Google Search | AI-Crawler (ChatGPT, Perplexity, Claude) | |
|---|---|---|
| Abruf | Indexierung (Stunden/Tage vorher) | Live-Fetch (Echtzeit) |
| JavaScript | Wird ausgeführt (Rendering) | Wird nicht ausgeführt |
| Relevante Metrik | LCP, CLS, INP (Browser-Metriken) | Server-Antwortzeit |
| Bei Timeout | Später nochmal versuchen | Seite wird übersprungen |
| Konsequenz | Ranking-Signal (weich) | Hard-Cutoff (drin oder draußen) |
Dein PageSpeed-Score kann 100 sein. Wenn der Server 800ms braucht, sieht ChatGPT trotzdem nichts. In klassischem SEO ist Server-Performance ein Tiebreaker. In GEO (Generative Engine Optimization) ist sie ein harter Ausschlussfaktor.
Eine Einschränkung: Google AI Overviews (die AI-generierten Antworten in der Google-Suche) nutzen Googles eigenen Index, nicht Live-Fetches. Für die AI-Sichtbarkeit bei Google gelten also die klassischen Crawling-Regeln. Die Tabelle oben bezieht sich auf AI-Dienste, die live abrufen: ChatGPT, Perplexity, Claude und Co.
Wer crawlt dich? Die wichtigsten AI-Bots
Bevor du misst, musst du wissen, wonach du suchst. Die kritischsten sind die „User“-Varianten: Sie feuern in dem Moment, in dem ein Mensch eine Frage stellt.
| Bot | Betreiber | Zweck |
|---|---|---|
ChatGPT-User | OpenAI | Nutzer-ausgelöstes Browsing |
Claude-User | Anthropic | Nutzer-ausgelöstes Browsing |
Perplexity-User | Perplexity | Nutzer-ausgelöstes Browsing |
Daneben gibt es weitere AI-Bots, die für Training und Index-Aufbau crawlen. Diese sind weniger zeitkritisch, aber für die Gesamtanalyse relevant:
Vollständige Bot-Übersicht (zum Aufklappen)
OpenAI:
GPTBot— Modell-TrainingOAI-SearchBot— ChatGPT-Search-Index
Anthropic:
ClaudeBot— Modell-TrainingClaude-SearchBot— Suchqualität
Perplexity:
PerplexityBot— Index-Aufbau
Weitere:
Google-Extended— Gemini-Training (kein Einfluss auf Google Search)Bytespider— ByteDance / TikTokCCBot— Common Crawl (offener Datensatz, den viele LLMs nutzen)Amazonbot— AmazonApplebot-Extended— Apple Intelligencemeta-externalagent— Meta
Vorbedingung: Blockierst du AI-Crawler?
Bevor du Antwortzeiten misst, stell sicher, dass AI-Crawler überhaupt auf deine Seite kommen. Prüf deine robots.txt:
# Beispiel: AI-Crawler erlauben
User-agent: GPTBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Perplexity-User
Allow: /Wenn dort Disallow: / für diese Bots steht, wirst du nie in AI-Antworten zitiert, egal wie schnell deine Antwortzeiten sind. Das ist eine bewusste Entscheidung, die jeder Seitenbetreiber für sich treffen muss. Aber sie sollte bewusst sein, nicht versehentlich.
Tipp: Anthropic unterstützt als einer der wenigen Anbieter die Crawl-delay-Direktive in der robots.txt. Damit lässt sich die Crawl-Frequenz begrenzen, ohne komplett zu blockieren.
Außerdem: Manche WAFs (Web Application Firewalls) oder Rate-Limiter blockieren AI-Crawler versehentlich, weil sie hohes Request-Volumen zeigen. GPTBot kann 30+ Requests pro Sekunde auf verschiedene URLs feuern. Das führt zu 403- oder 429-Fehlern statt Timeouts. Auch das sollte die IT prüfen.
AccessLogs: Warum sie für AI-Sichtbarkeit unverzichtbar sind
Wer wissen will, wie schnell sein Server auf AI-Crawler antwortet, muss ins AccessLog schauen. Tools wie Oncrawl oder Lumar können AI-Bot User-Agents aus Logfiles auswerten, aber ein zentrales Dashboard wie die Google Search Console gibt es für AI-Crawling noch nicht. AccessLogs sind dasselbe Werkzeug, das SEOs schon für die Googlebot-Analyse kennen — nur mit anderen User-Agents.
Datenschutz: IP-Adressen anonymisieren
AccessLogs enthalten standardmäßig vollständige IP-Adressen. Die sind personenbezogene Daten (DSGVO). Für die Bot-Analyse braucht man sie nicht, der User-Agent reicht. Wenn die IT Logs an SEOs weitergibt oder länger speichert, sollten die IP-Adressen vorher anonymisiert werden.
Zwei Ansätze:
- Beim Export: IP-Adressen durch einen Platzhalter ersetzen, bevor die Daten das Server-Team verlassen. Bei IPv4 die letzten zwei Oktette nullen (192.168.123.45 → 192.168.0.0), bei IPv6 alles nach dem dritten Block kürzen (2001:db8:abcd:1234:… → 2001:db8:abcd::). Ein simples
sedreicht dafür. - Direkt am Server: nginx und Apache lassen sich so konfigurieren, dass IP-Adressen gar nicht erst vollständig gespeichert werden. Das ist die sauberere Lösung.
Prüf-Checkliste: 3 Fragen an deine IT
Wenn du SEO oder E-Commerce-Manager bist: Hier sind die drei Fragen, die du deiner IT stellen solltest.
1. „Enthalten unsere AccessLogs die Server-Antwortzeit?“
Standard-AccessLogs protokollieren Zeitstempel, URL und Statuscode, aber nicht, wie lange der Server gebraucht hat. Die Antwortzeit muss explizit konfiguriert werden.
2. „Sehen wir AI-Crawler in unseren Logs?“
Wenn die IT mit „Welche AI-Crawler?“ antwortet, ist das ein guter Anlass, gemeinsam hinzuschauen. Und: Manche Serverkonfigurationen filtern Bot-Traffic aus den Logs heraus, um Speicherplatz zu sparen oder Rauschen zu reduzieren. Wenn AI-Crawler in dieser Filterliste stehen, tauchen sie in den Logs gar nicht auf.
3. „Wie schnell antwortet unser Server auf AI-Crawler-Anfragen?“
Nicht nach dem Durchschnitt fragen, sondern nach dem p95. Kurz erklärt: Sortiere alle Antwortzeiten von schnell nach langsam. Der p95-Wert ist die Antwortzeit, die 95% aller Anfragen unterschreiten. Nur die langsamsten 5% sind langsamer. Der Durchschnitt verschleiert Ausreißer, p95 zeigt das reale Problem. Wenn der über 500ms liegt, lohnt sich ein genauerer Blick.
Sofort-Check ohne IT: In der Google Search Console unter Einstellungen > Crawling-Statistiken siehst du die durchschnittliche Antwortzeit für Googlebot. Das ist kein AI-Crawler, aber ein erster Anhaltspunkt. Wenn Googlebot schon über 500ms sieht, werden AI-Crawler auch Probleme haben.
Ticket-Vorlage zum Kopieren
Technische Anleitung für nginx und Apache: Server-Antwortzeiten für AI-Crawler messen
Betreff: AccessLog um Antwortzeiten erweitern + AI-Crawler-Auswertung
Warum:
Immer mehr Nutzer suchen über AI-Suchmaschinen wie ChatGPT, Perplexity und Claude. Damit unsere Inhalte dort zitiert werden können, müssen die AI-Crawler unsere Seiten abrufen können. Das tun sie live, in Echtzeit. Antwortet unser Server zu langsam (beobachtete Schwelle: ~500ms), bricht der Crawler ab und eine andere Quelle wird zitiert. Wir müssen wissen, ob unsere Antwortzeiten schnell genug sind.
Bitte:
- AccessLog um die Server-Antwortzeit erweitern (Anleitung: nginx/Apache-Konfiguration)
- Prüfen, ob AI-Crawler-Requests in den Logs überhaupt auftauchen (User-Agents: ChatGPT-User, Claude-User, Perplexity-User, GPTBot, ClaudeBot, PerplexityBot)
- Einmalige Auswertung: Wie viele Requests von AI-Crawlern? Wie hoch ist die durchschnittliche und p95-Antwortzeit? Je nach Ergebnis brauchen wir die Auswertung in den folgenden Wochen erneut — falls es sich lohnt, die Schritte zu dokumentieren oder zu automatisieren.
- Ergebnis an mich zurückmelden
Umfang:
Log-Format um eine Variable erweitern, Reload, Auswertung per Shell-Einzeiler. Technische Anleitung im verlinkten Blogpost.
Nicht sicher, wo du stehst? Das hängt vom Tech-Setup ab. AccessLogs, Monitoring-Tools und Optimierungswege unterscheiden sich je nach Plattform und Infrastruktur. Ich unterstütze bei der Einordnung, als Sparring-Partner für dein Team oder als externer Blick auf deine Logs.
Ergebnisse einordnen
Wenn die IT die Auswertung liefert, hier die Einordnung:
| p95-Antwortzeit | Bewertung |
|---|---|
| Unter 200ms | Sehr gut, kein Handlungsbedarf |
| 200-500ms | Akzeptabel, regelmäßig beobachten |
| Über 500ms | Problematisch, Optimierung priorisieren |
| Über 800ms | Kritisch, sofort handeln |
Wie diese Zahlen in der Praxis aussehen
Damit die Skala nicht abstrakt bleibt. Zwei Projekte, bei denen genau diese Messung der Ausgangspunkt war:
- WordPress-Seite: 800ms → unter 300ms nach Server-Tuning
- Legacy-PHP-Shop: 1535ms → 690ms (-55%) durch Code-Optimierung. Und das Update von PHP auf 8.x steht noch aus.
Die Optimierung selbst ist nicht Thema dieses Artikels. Aber die Messung war in beiden Fällen der erste Schritt. Ohne sie wäre das Problem unsichtbar geblieben.
So sah die Auswertung in einem meiner Projekte aus (Antwortzeiten pro URL, gruppiert nach AI-Bot-Requests über 14 Tage):
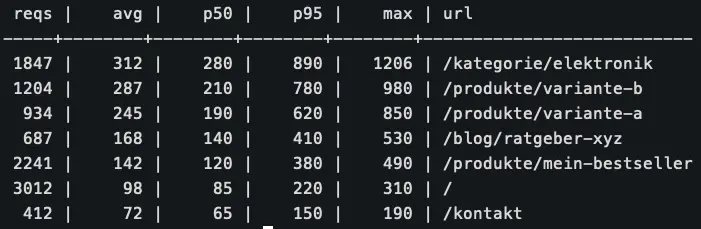
Kategorie-Seiten und Produktvarianten sind die langsamsten URLs, weil dort die meisten Datenbankabfragen ausgelöst werden. Die Startseite profitiert am stärksten vom Cache.
Sonderfall: Shopify und Managed-Hosting-Plattformen
Wer auf Shopify, Squarespace oder einer anderen Managed-Plattform arbeitet, hat keinen Zugang zu Serverlogs und kann keine nginx- oder Apache-Konfiguration ändern. Die Ticket-Vorlage oben hilft hier nicht.
Aber das heißt nicht, dass man nichts tun kann.
Wie ist die Ausgangslage?
Shopify cached serverseitig. Die Antwortzeiten liegen typischerweise zwischen 200 und 600ms, je nach Theme-Komplexität und Anzahl installierter Apps. Allerdings schwanken sie bei Shopify mitunter um Faktor 4. Ein paar Stichproben per curl reichen deshalb nicht aus. Überladene Liquid-Templates und zu viele Apps, die bei jedem Request serverseitig Code ausführen, können die Antwortzeit zusätzlich auf 800ms+ treiben.
Was du messen kannst:
- curl-Schnelltest (funktioniert bei jeder URL, siehe unten). Gut für einen ersten Eindruck, aber wegen der Schwankungen nicht repräsentativ.
- Google Search Console > Einstellungen > Crawling-Statistiken: zeigt durchschnittliche Antwortzeiten für Googlebot. Nicht identisch mit AI-Crawlern, aber ein Anhaltspunkt.
- Externe Crawling-Tools wie Screaming Frog, Oncrawl oder Lumar können Antwortzeiten pro URL messen.
- Kontinuierliches Monitoring mit einem RUM-Tool wie RUMvision. Gerade bei Shopify, wo die Antwortzeiten stark schwanken, braucht man echte Langzeit-Daten statt einzelner Stichproben.
Technische Umsetzung: Antwortzeiten im AccessLog erfassen
Ab hier beginnt der technische Teil.
nginx
nginx bietet zwei relevante Variablen:
| Variable | Was sie misst |
|---|---|
$request_time | Gesamtzeit vom ersten Client-Byte bis zum letzten Response-Byte |
$upstream_response_time | Reine Backend-Antwortzeit (PHP, Node, etc.) |
Für AI-Crawler zählt $request_time: die Gesamtzeit aus Sicht des Clients, inklusive Backend-Verarbeitung und Netzwerkübertragung. Das entspricht dem, was der Crawler tatsächlich erlebt. $upstream_response_time ist trotzdem nützlich: Wenn $request_time zu hoch ist, zeigt der Vergleich mit $upstream_response_time, ob das Problem im Backend liegt oder in der Netzwerkübertragung. Achtung: $upstream_response_time liefert -, wenn kein Backend angesprochen wird (z.B. bei statischen Dateien). In der JSON-Config steht der Wert deshalb als String. Bei der Auswertung mit jq ggf. mit select(.upstream_response_time != "-") filtern.
Nach jeder Config-Änderung: nginx -t zum Testen, dann nginx -s reload für einen Reload ohne Downtime (kein Restart).
Standard-Format mit Antwortzeit:
log_format timed '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" '
'rt=$request_time urt=$upstream_response_time';
access_log /var/log/nginx/access.log timed;Beispiel-Zeile:
66.249.66.1 - - [12/Mar/2026:14:22:01 +0100] "GET /produkte/mein-bestseller HTTP/1.1" 200 14532 "-" "ChatGPT-User/1.0" rt=0.048 urt=0.045Apache
Apache nutzt %D (Mikrosekunden) oder %{ms}T (Millisekunden):
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %D" combined_with_time
CustomLog ${APACHE_LOG_DIR}/access.log combined_with_timeBeispiel-Zeile:
66.249.66.1 - - [12/Mar/2026:14:22:01 +0100] "GET /produkte/mein-bestseller HTTP/1.1" 200 14532 "-" "ChatGPT-User/1.0" 4823048230 = 48.230 Mikrosekunden = ~48ms.
Bonus: Log als JSON formatieren (Empfehlung)
JSON-Logs lassen sich maschinell auswerten, ohne reguläre Ausdrücke parsen zu müssen. Wer später mit jq, ELK oder einem anderen Tool arbeiten will, spart sich den Parsing-Schritt.
nginx (mit escape=json für korrektes Escaping, ab nginx 1.11.8):
log_format json_log escape=json
'{'
'"timestamp":"$time_iso8601",'
'"remote_addr":"$remote_addr",'
'"method":"$request_method",'
'"url":"$request_uri",'
'"status":$status,'
'"bytes":$body_bytes_sent,'
'"user_agent":"$http_user_agent",'
'"request_time":$request_time,'
'"upstream_response_time":"$upstream_response_time"'
'}';
access_log /var/log/nginx/access_json.log json_log;Nicht vergessen: Logrotation für die neue Logdatei einrichten (/etc/logrotate.d/), damit die Festplatte nicht voll läuft.
Apache:
# Hinweis: %z erzeugt "+0100" statt "+01:00" (kein Doppelpunkt). Die meisten Log-Shipper
# (Filebeat, Vector) parsen beide Formate. Falls nicht: Zeitzone im Shipper-Config anpassen.
LogFormat \
"{\"timestamp\":\"%{%Y-%m-%dT%H:%M:%S%z}t\",\"remote_addr\":\"%a\",\"method\":\"%m\",\"url\":\"%U%q\",\"status\":%>s,\"bytes\":%B,\"user_agent\":\"%{User-Agent}i\",\"response_time_us\":%D}" \
json_log
CustomLog ${APACHE_LOG_DIR}/access_json.log json_logHinweis: Anders als nginx (escape=json) hat Apache kein eingebautes JSON-Escaping für LogFormat. Apaches Standard-Escaping von " und \ in Header-Werten reicht in der Praxis für die meisten Logzeilen. Bei exotischen User-Agents mit Sonderzeichen kann das JSON aber invalide werden. Wer die Logs an einen ELK-Stack oder ein ähnliches System weiterleitet, lässt den Log-Shipper (Filebeat, Vector) fehlerhafte Zeilen abfangen.
Auswertung: AI-Crawler-Performance analysieren
Die folgenden Befehle nutzen Standard-Unix-Tools (grep, jq, sort, awk) und das JSON-Log-Format von oben. jq lässt sich mit apt install jq / yum install jq nachrüsten, der Rest ist auf jedem Linux-Server vorinstalliert. Die awk-Befehle nutzen asort(), das GNU awk voraussetzt (auf Linux-Servern Standard, auf macOS ggf. gawk per brew install gawk nachrüsten und anstatt awk nutzen).
Die JSON-Logs sind im JSONL-Format (ein Objekt pro Zeile). jq verarbeitet sie zeilenweise im Stream, sort nutzt bei großen Datenmengen automatisch Temp-Dateien. Die Pipelines funktionieren damit auch bei Logfiles im Gigabyte-Bereich, ohne den Arbeitsspeicher zu sprengen.
Welche AI-Bots crawlen mich?
grep -Eo '"user_agent":"[^"]*"' access_json.log \
| grep -Ei "GPTBot|ChatGPT-User|OAI-SearchBot|ClaudeBot|Claude-User|PerplexityBot|Perplexity-User|Bytespider" \
| sort | uniq -c | sort -rnStatuscodes pro Bot prüfen
403er oder 429er deuten darauf hin, dass eine WAF oder ein Rate-Limiter die Crawler blockiert. 5xx-Fehler zeigen Serverprobleme. Hinweis zu den folgenden Befehlen: Manche Bots senden einen vollständigen Mozilla-User-Agent (z.B. Mozilla/5.0 (compatible; GPTBot/1.0; ...)). Die jq-Extraktion zeigt dann „Mozilla“ statt des Bot-Namens. Die Gruppierung ist trotzdem korrekt, weil der grep vorher nur Zeilen mit dem richtigen Bot-Namen durchlässt. Wer saubere Labels braucht, kann im jq-Ausdruck stattdessen nach dem Bot-Namen im UA-String suchen.
grep -E "ChatGPT-User|Claude-User|Perplexity-User|ClaudeBot|PerplexityBot|GPTBot" access_json.log \
| jq -r '[(.user_agent | split(" ")[0] | split("/")[0]), (.status | tostring)] | join(" ")' \
| sort | uniq -c | sort -rnDurchschnittliche Antwortzeit pro Bot
# Für nginx-Logs (request_time in Sekunden)
grep -E "ChatGPT-User|Claude-User|Perplexity-User|ClaudeBot|PerplexityBot|GPTBot" access_json.log \
| jq -r 'select(.status == 200) | [(.user_agent | split(" ")[0] | split("/")[0]), (.request_time * 1000 | round | tostring)] | join(" ")' \
| awk '{sum[$1]+=$2; n[$1]++} END {for (bot in sum) printf "%s: %dms avg (%d requests)\n", bot, sum[bot]/n[bot], n[bot]}' \
| sort -t: -k2 -rnAntwortzeiten pro URL mit Perzentilen
Die folgende Auswertung gruppiert nach URL und zeigt für jede URL die Anzahl der Requests, den Durchschnitt und die Perzentile. So siehst du direkt, welche URLs problematisch sind und ob genug Datenpunkte vorhanden sind, um den Werten zu vertrauen:
grep -E "ChatGPT-User|Claude-User|Perplexity-User|ClaudeBot|PerplexityBot|GPTBot" access_json.log \
| jq -r 'select(.status == 200) | [.url, (.request_time * 1000 | round | tostring)] | join("\t")' \
| sort -t$'\t' -k1,1 \
| awk -F'\t' '
function ceil(x) { return (x == int(x)) ? x : int(x) + 1 }
function percentile(arr, n, p, rank) { rank = ceil(n * p); return arr[rank < 1 ? 1 : rank] }
function dump() {
if (n < 1) return
asort(vals)
printf "%4d | %6d | %6d | %6d | %6d | %s\n",
n, sum/n, percentile(vals,n,0.50), percentile(vals,n,0.95), vals[n], url
}
BEGIN {
printf "%4s | %6s | %6s | %6s | %6s | %s\n", "reqs", "avg", "p50", "p95", "max", "url"
printf "-----+--------+--------+--------+--------+---------------------------\n"
}
$1 != url { dump(); url=$1; n=0; sum=0; delete vals }
{ n++; sum+=$2; vals[n]=$2 }
END { dump() }
' \
| tail -n +3 \
| sort -t'|' -k4,4 -rn \
| head -20Alle Zeitwerte sind in Millisekunden. Die Ausgabe ist nach p95 sortiert (höchste zuerst). URLs mit wenigen Requests (z.B. unter 10) liefern keine belastbaren Perzentile. Wenn der p95 über 500ms liegt, lohnt sich ein genauerer Blick auf diese URL.
Schnelltest ohne JSON-Log: Antwortzeit mit curl messen
Kein JSON-Log konfiguriert? Für einen schnellen Einmaltest reicht curl:
curl -s -o /dev/null -w "Antwortzeit: %{time_total}s\n" https://www.example.com/Das misst die gesamte Antwortzeit inkl. Download. Unter 200ms: gut. Über 500ms: genauer hinschauen.
Einschränkung: curl misst von deinem Standort aus. AI-Crawler sitzen in US-Rechenzentren. Wer näher an der Realität messen will, kann einen VPS in den USA nutzen oder Tools wie WebPageTest mit US-Teststandort verwenden.
Logging-Pipeline statt jq
jq ist perfekt für einmalige Analysen. Wer Logs dauerhaft monitoren will, braucht eine Pipeline. Gängige Lösungen sind der ELK-Stack (Elasticsearch, Logstash, Kibana), Grafana Loki (besonders in Kubernetes-Umgebungen verbreitet) oder Managed-Dienste wie Datadog. Die JSON-Log-Formate oben lassen sich direkt in diese Systeme einlesen. Deine IT hat dafür vermutlich schon eine Lösung am Start. Wer noch keine solche Infrastruktur hat: Die jq-Auswertungen oben reichen für den Einstieg völlig.
Häufigste Ursachen langsamer Antwortzeiten
Wenn die Auswertung zeigt, dass die Antwortzeiten zu hoch sind, hier die üblichen Verdächtigen. Grundsätzlich gilt: Erst messen und profilen, dann gezielt optimieren. Nicht blind irgendwelche Stellschrauben drehen. Manche Probleme lassen sich mit mehr Hardware entschärfen, häufig liegt die Ursache aber im Code. Und in der Regel nicht im Framework, sondern im Customizing.
1. CDN oder Full-Page-Cache nicht vorhanden oder nicht wirksam
Wenn ein CDN eine gecachte HTML-Antwort in 20ms ausliefert, ist das Antwortzeit-Problem gelöst. Ein serverseitiger Full-Page-Cache (Varnish, WP Super Cache) hat denselben Effekt. Aber: Ein CDN zu haben heißt nicht, dass es auch HTML cachet.
In der Praxis werden HTML-Seiten häufig vom CDN-Caching ausgenommen. Die Gründe sind vielfältig: dynamische Inhalte (Preise, Lagerbestände, Warenkorb, „eingeloggt als“), GeoIP-Anpassungen (Sprache, Währung), oder weil die Anwendung GET-Requests verwendet, die Seiteneffekte auslösen (z.B. Tracking-Pixel, Session-Initialisierung). In solchen Fällen fließt jeder Request durch das CDN hindurch zum Origin-Server. Die Antwortzeit ist dann genauso langsam wie ohne CDN.
Deshalb gilt: Auch mit CDN die Antwortzeiten messen. Die Auswertung oben zeigt, was tatsächlich beim Crawler ankommt, egal ob ein CDN davor sitzt oder nicht.
Wer HTML-Caching aktivieren will, braucht eine Strategie: Was wird gecacht? Wie lange? Wie wird zwischen eingeloggten und anonymen Nutzern unterschieden? Welche HTTP-Methoden sind cachebar? Wann werden Caches invalidiert, z.B. bei Änderungen an Lagerbestand oder Produktverfügbarkeit? Und wer dynamische Fragmente auf einer sonst statischen Seite hat (z.B. Warenkorb-Icon, Login-Status), kann mit Edge Side Includes (ESI) den Großteil der Seite cachen und nur die dynamischen Teile am Edge zusammensetzen.
Weiterer Fallstrick: Query-Parameter im Cache-Key. Für das CDN ist /produkte/mein-bestseller?fbclid=IwAR3x eine andere Ressource als /produkte/mein-bestseller. Click-IDs wie fbclid (Meta), gclid (Google Ads) und msclkid (Bing) sind pro Klick eindeutig. Jeder Aufruf mit einer solchen ID ist ein garantierter Cache-Miss. Auch UTM-Parameter aus Newslettern oder Social-Media-Posts erzeugen eigene Cache-Keys. Ohne explizite Konfiguration, die bekannte Tracking-Parameter beim Cache-Key ignoriert, wird der Cache systematisch unterlaufen. Das betrifft nicht nur AI-Crawler, sondern alle Besucher, reduziert aber die Cache-Hit-Rate und damit die durchschnittliche Antwortzeit, die auch AI-Crawler erleben.
2. Langsame Datenbank-Queries
Fehlende Indizes oder überladene Abfragen. Slow-Query-Log aktivieren und die langsamsten Queries optimieren.
3. Kein Server-Side Rendering
Single-Page-Apps (React, Vue) ohne SSR oder SSG liefern ein leeres HTML-Gerüst. AI-Crawler führen kein JavaScript aus und sehen buchstäblich nichts. SSG (Static Site Generation) ist die radikalste Lösung: HTML liegt fertig auf der Platte, die Antwortzeit ist minimal.
4. Langsamer Anwendungscode
Häufig bei PHP-Anwendungen (WordPress, WooCommerce, Magento, Shopware): verschachtelte Schleifen, redundante API-Calls, fehlende Caching-Schichten im Code. Auch die PHP-Version spielt eine Rolle: PHP 8.x brachte gegenüber PHP 7.x messbare Performance-Verbesserungen durch interne Optimierungen und einen verbesserten Opcache. Wer noch auf PHP 7.x läuft, sollte ein Upgrade in Betracht ziehen. Profiling-Tools (Xdebug, Blackfire, Tideways) helfen, die tatsächlichen Engpässe zu finden, statt zu raten.
5. Überladene Middleware und Plugins
Jedes Plugin, das bei jedem Request läuft, addiert Millisekunden. Bei WordPress-Shops mit 30+ Plugins summiert sich das schnell.
6. Shared Hosting und veraltete Hardware
Wenn 200 andere Shops auf demselben Server laufen, wird es bei Lastspitzen eng. Ein weiteres Problem: Hosting-Pakete, die vor Jahren gebucht und seitdem nie auf aktuelle Hardware umgezogen wurden. Was damals ausreichend war, kann mit steigendem AI-Crawler-Traffic zum Engpass werden.
Fazit
Schnelle Server-Antwortzeiten sind kein Garant für AI-Sichtbarkeit. Content-Qualität, Strukturierung und Autorität spielen weiterhin eine Rolle. Aber sie sind die technische Voraussetzung, damit GEO (Generative Engine Optimization) überhaupt greifen kann. Ohne schnelle Antwortzeiten kommen AI-Crawler gar nicht erst an deinen Inhalt. Wie man diese erreicht, ist ein Thema für sich.
Die reine Technik ist überschaubar: AccessLog konfigurieren, nach AI-Bots filtern, Antwortzeiten auswerten. Je nach Infrastruktur- und Prozesskomplexität kann der Gesamtaufwand variieren. Danach die Auswertung alle 14 Tage wiederholen. Das entspricht einer gängigen Log-Retention-Zeit und zeigt Trends frühzeitig.
Die Optimierung danach kann komplex sein. Aber erst messen, dann gezielt optimieren. Durch Profiling lässt sich auch in komplexen und gewachsenen Systemen schnell herausfinden, wo die Zeit verloren geht.
Messen ist der erste Schritt. Optimieren der zweite.
Ich unterstütze E-Commerce-Teams ihre Server-Antwortzeiten in den grünen Bereich zu bringen. Durch Profiling, Caching-Strategie und Code-Optimierung. Egal ob Shopify, Oxid oder gewachsenes Legacy-Projekt.

Fullstack Performance Tuner
Quellen:
- Jérôme Salomon: HTTP 499-Analyse, ChatGPT-User-Agent
- OMT Summit 2026: Johan von Hülsen, Vortrag zu AI-Crawl-Verhalten
- Cloudflare Blog: „From Googlebot to GPTBot: who’s crawling your site in 2025“
- OpenAI: Bot-Dokumentation
- Anthropic: Crawler-Dokumentation
- Perplexity: Bot-Dokumentation